隐藏 Win11 任务栏里 Chrome 图标上的头像
Chrome 的登录用户在任务栏里的图标右上角会显示个人资料头像,隐藏办法:任务栏上空白处点右键 > 任务栏设置 > 任务栏行为 > 取消勾选“在任务栏应用上显示徽章”。
生命不息,折腾不止,一个80后老猫的网络日常
Chrome 的登录用户在任务栏里的图标右上角会显示个人资料头像,隐藏办法:任务栏上空白处点右键 > 任务栏设置 > 任务栏行为 > 取消勾选“在任务栏应用上显示徽章”。
分析 TW DNS RPZ 网络封锁与解锁策略,域名遭劫持时常见“此网域已经遭到封锁”提示,厘清政府管控机制并使用 DoH、VPN 等方式绕过限制,并评估政策成效与隐私风险,归纳成人内容与盗版网站如何受此影响,透过实例与图解说明 DNS 拦截运作机制与自订浏览器、手机 DoH 配置,说明自由与审查交错下的种种冲击。
艺人黄子佼近期卷入桃色风波,该事件引发广泛关注并促使媒体报导“创意私房已关闭”的消息。许多出于好奇心尝试访问该网站的使用者,却发现其网址遭到劫持,最终被导向台湾网络资讯中心(TWNIC)设置的封锁页面。
台湾网络资讯中心(Taiwan network information center,TWNIC)是管理台湾网域(.tw、.台湾)与 IP 位址的机构,负责网络资源分配、技术教育推广、国际合作及网络安全发展。
网络本质上是自由的,这里所谓的自由指的是使用者能够连线到任意网站。然而,受到法规限制的影响,政府可能会控制或禁止部分特定网页的存取。例如,在中国大陆,常见的被封锁对象包括 Google、YouTube、Facebook、维基百科 等
网络自由并不意味着对色情、赌博、盗版等行为的容忍或鼓励,尤其当这些活动建立在剥削他人痛苦或侵犯他人权益的基础上时。这些行为本质上就不应受到支持或许可,且若有人因接触此类内容而进一步涉入犯罪或非法活动,将可能引发更严重的社会问题。
而台湾早在 2013 年,因应国内外部分网站提供侵权内容的情况,智慧财产局曾建议国内 ISP 采用 DNS 或封锁 IP 的方式进行阻挡,但最终未能落实。
在近期新闻媒体的渲染下,当使用者点选创意私房时,便会发现其网址被转导至封锁页面。事实上,自 2020-03-30 日起,TWNIC(财团法人台湾网络资讯中心)召开了第一次 DNS RPZ 会议,并透过 DNS 等方式进行网络封锁持续至今。
域名系统回应政策区域(domain name system response policy zone,DNS RPZ)是一项由 互联网系统联盟 开发的技术,旨在于 DNS 服务器层级实现网址过滤机制。
RPZ 允许网络管理员在 DNS 服务器中配置特殊的回应政策区域,当查询涉及受限制的域名时,该 DNS 服务器将依据预设策略,回传指定的 IP 位址或错误讯息,借此将流量重定向或阻断,从而有效防范访问恶意网站、钓鱼网站或政治不正确的内容。
举例而言,若使用者欲浏览 google.com,其正确 IP 位址为 1.2.3.4,但若该网域已被列入中华电信(DNS 服务器 IP:168.95.1.1)的 RPZ 过滤名单中,DNS 解析后将回传 NXDOMAIN 或被重定向至特定 IP 位址,导致无法正常取得该网站内容。
相对地,若将 DNS 服务器改为使用未参与 RPZ 过滤的公共 DNS 服务(如 CloudFlare 的 1.1.1.1),则在解析 google.com 时不受过滤名单影响,能够正常解析并取得该网站的原始内容。
根据 2024/04 撷取自TWNIC的资料,目前已参与该机制的成员包括:
教育部(Ministry of Education Republic of China)
中华电信(Chunghwa Telecom)
台湾硕网(So-net Taiwan)
宏远电讯(SaveCom International)
中嘉和网(KBT)
大台中数位有线电视(VeeTIME Corp.)
天外天数位有线电视(TWT Digital Communication Corporation)
正源科技(Yulon IT Solutions)
台湾固网(台湾大哥大)(Taiwan Fixed Network)
新世纪资通(远传)(New Century InfoComm Tech,NCIC)
亚太电信(Asia Pacific Telecom,APT)
台湾之星(Taiwan Star Telecom,T Star)
三大有线电视(SAN DA CATV)
公共电视(Public Television Service,PTS)
统一资讯(President Information)
换言之,如果使用的是中华电信、台湾固网、远传等网络服务,其预设的 DNS 服务器皆会透过 RPZ 进行过滤。
域名解析的核心功能在于将网址转换成相应的 IP 位址。当我们将网址提交给 DNS 服务器时,该服务器仅会记录使用者请求的域名,而不会接触到网页内容或传输的敏感资讯(例如密码、个人资料)。DNS 服务器会回传经过过滤或确认安全的 IP 位址,确保使用者能够安全地连线。
例如,当使用者尝试浏览 NSFW.com,若其域名遭到劫持而回传 150.242.101.120,浏览器将比对该连线的凭证。若凭证与预期域名不一致或连线使用 HTTP 协定,则会显示不安全提示。使用者若选择忽略警告,则最终会被重定向到 TWNIC 设置的封锁页面。
此外,若电脑的“受信任根凭证”遭窜改,即使域名被劫持且信任了可疑凭证,浏览器也可能无法发出有效警告,从而使攻击者得以执行中间人攻击(MITM),进一步拦截和解析所有网页传输内容,实施更精确的封锁。因此,在使用公共电脑时,建议避免进行登入等敏感操作,以降低安全风险。
对于相关应用,使用者可以自行建立 DNS 服务器来过滤广告、病毒、色情及钓鱼网站等不良内容,自建的 DNS 服务器在功能上与 RPZ 相似。目前市场上有现成方案,例如免费的 NextDNS 或可自行架设的开源工具 AdGuardHome。
上述内容说明,实际上只是 DNS 解析中被套用一层 RPZ 而已。若要正常浏览网站,建议不要使用这些机构预设所提供的 DNS 服务器。较新一代的系统可以透过设定 DNS over HTTPS(DoH)来防范攻击者伪造 DNS 讯息。从网络管理员的角度来看,DoH 流量会与其他 HTTPS 流量相同,进而使网管更难追踪使用者浏览的网页。
步骤 1:开启浏览器的设定
步骤 2:搜寻并输入 DNS,填入 DoH 网址后,即可正常解析网页。
在手机装置上,大部分新系统均支援 DNS over HTTPS(DoH)。以 iPhone 为例,可透过安装 mobileconfig 设定档 来启用此功能。安装完成后,手机所有流量将透过指定的 DNS 服务器进行解析,您可以选择 Google、Cloudflare 或 Quad9 等公认的 DNS 服务器。
点击上述连结后,选择允许安装描述档。
前往系统中的“设定”→“一般”→“VPN 与装置管理”。
在“已下载的描述档”中,找到 Cloudflare DNS over HTTPS 描述档,然后点选右上角的“安装”。
进入“DNS”设定,将“自动”切换为“Cloudflare DNS over HTTPS”。
完成以上步骤后,您的手机将以 DoH 方式查询域名,有效避免 DNS 劫持并提升使用者隐私保护。
备注: 请注意,DNS over HTTPS(DoH)仅为加密 DNS 查询的技术,并不等同于虚拟私人网络(VPN)。
网络审查是一项极为复杂的议题,涉及政府、企业与使用者之间的持续对抗。以大陆为例,使用者冒着违法风险利用 VPN,并结合各种加密协定(如 Shadowsocks、V2ray、Trojan、Hysteria、Juicity、WireGuard、Snell)进行翻墙;而在台湾,市面上充斥着各式 VPN 服务,付费订阅后即可绕过相关限制,最终仅使 VPN 供应商、中间商与 VPS 供应商获利。
此外,若网站遭封锁,网站主只需更换域名,即可让政府难以及时封锁。甚至透过 TG、Line、FB 与各类私密群组分享、贩售该类内容,使得封锁措施形同虚设。正如新闻媒体渲染的“创意私房已关闭”讯息,反而令更多人认识该网站。
成人内容产业涉及广泛的伦理与法律问题,但当市场需求存在时,即使花费巨额资金取得内容,产业仍难以彻底瓦解。真正的解决之道在于释出高额奖金以捉拿幕后操控者(例如拍摄者或诈骗广告投递者),并实施严格法律制裁;对于屡次违规者,则采取全面封锁措施。
然而,色情产业是否能够真正根除仍存疑问:想观看的人总能找到方法,甚至不惜支付更高金额获得内容。值得一提的是,Apple 于 2021 年曾提出儿童性虐待素材(child sexual abuse material,CSAM)检测系统,计划透过比对使用者 iCloud 照片与儿童保护组织提供的已知 CSAM 图片杂凑值来侦测相关素材,但最终因争议与准确性问题而未获推行。
期盼未来能有更完善的措施,减少因胁迫而拍摄的不良影片与缺乏内容、没营养价值的诈骗垃圾广告,让这个世界变得更加美好。
失业的打击就像一场毫无征兆的秋雨,打湿了曾经那个自命不凡地自己。人生的所有曲折似乎在此时此刻彼此呼应,而今天我的处境,可能也正是许多人正要面临的窘境。
对于我来说,失业不仅仅是经济上的挫折,更是一次被迫的自我审视。在经历从收入丰厚到陷入困顿的转变后,内心的煎熬远比金钱的缺乏更加难以承受。
即使已经读过无数“如何应对失业”的建议,但当失业真正发生在自己身上时,却都显得苍白无力。当面对家庭的琐事和压力,每天醒来发现生活依旧难题重重时,难免开始怀疑。
同时,现实不可能因你的积极心态而变好,也不会因为学习了新技能就马上能获得一个能养家糊口的工作。此时,可能会让你更加的怀疑人生。
未来的路该怎么走?甚至是,自己是否具备应对新挑战的能力?开始陷入无尽的自我怀疑中……
无论30岁还是40岁,人生各阶段都有不同的难关。尽管艰难,但往往只能靠自己一步步挺过来。你感到焦虑、迷茫的原因,或许在于失去经济来源带来的家庭压力,让生活变得更加艰难。失业切断了收入的来源,这是对任何人来说都难以承受的考验。
失业期间,你可能会怀疑自己的价值,担心未来,但请记得,这些情绪都是正常的。也许,失业未必完全是坏事。许多人在职场上看似忙碌,实则原地踏步,甚至不断退步。一直得过且过,逐渐失去斗志。而失业反倒可能成为一次新的开始。
尽管这是一个痛苦的过程,却也是促使我成长的必经之路。无论是创业,还是借助朋友的帮助,先解决眼前的燃眉之急。假如回顾人脉网络,发现周围的朋友并不可靠,甚至阻碍你前行,或许更深层的问题并不只是失业,而是要重新审视自己与他人关系的本质。
失业可能会带来沮丧和压力,但最令人绝望的并非失去工作,而是放弃寻找新的可能性。朋友,务必要坚持下去,竭尽全力地拯救自己,不管过程多么艰难,都不要轻易放弃。妥协和退缩只会让人困于泥潭,而充满勇气的挣扎才能带来希望和成长。
陌生的朋友,祝好。
在AI兴起之前,一直在用的代码,分享给盆友们~
Mozilla Readability.js 的 PHP 端口。解析 html(通常是新闻和文章)返回标题、作者、主图像和文本内容(最新版可用属性)。分析每个节点,给它们打分,并确定哪些是相关的,哪些可以丢弃。
算法原作者:https://github.com/mingcheng/php-readability/
算法新版:https://github.com/andreskrey/readability.php(该项目已经废弃)
算法最新版:https://github.com/fivefilters/readability.php
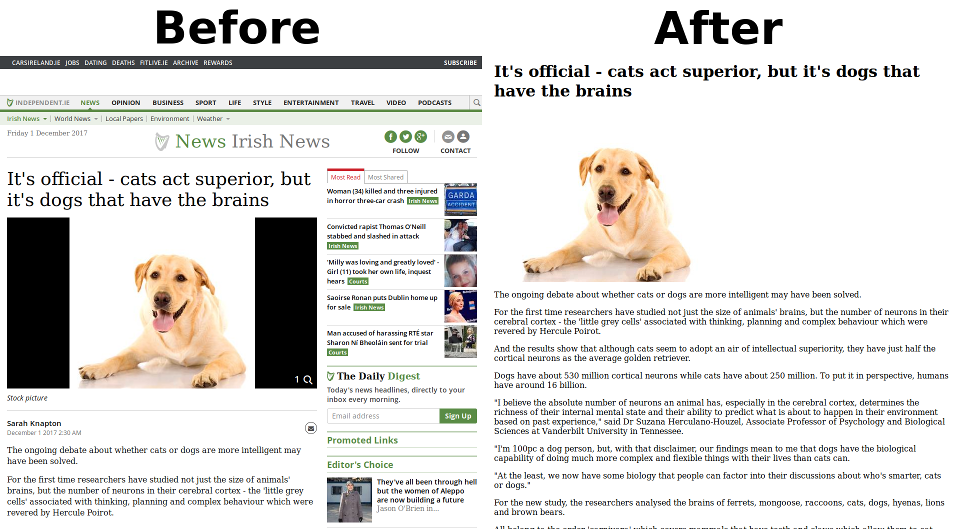
require 'Readability.php'; $html = "整个html页面"; $Readability = new Readability($html); $ReadabilityData = $Readability->getContent(); //var_dump($ReadabilityData); echo "<h1>".$ReadabilityData['title']."</h1>"; echo $ReadabilityData['content'];
Readability.php
class Readability {
// 保存判定结果的标记位名称
const ATTR_CONTENT_SCORE = "contentScore";
// DOM 解析类目前只支持 UTF-8 编码
const DOM_DEFAULT_CHARSET = "utf-8";
// 当判定失败时显示的内容
const MESSAGE_CAN_NOT_GET = "Readability was unable to parse this page for content.";
// DOM 解析类(PHP5 已内置)
protected $DOM = null;
// 需要解析的源代码
protected $source = "";
// 章节的父元素列表
private $parentNodes = array();
// 需要删除的标签
// Note: added extra tags from https://github.com/ridcully
private $junkTags = Array("style", "form", "iframe", "script", "button", "input", "textarea",
"noscript", "select", "option", "object", "applet", "basefont",
"bgsound", "blink", "canvas", "command", "menu", "nav", "datalist",
"embed", "frame", "frameset", "keygen", "label", "marquee", "link");
// 需要删除的属性
private $junkAttrs = Array("style", "class", "onclick", "onmouseover", "align", "border", "margin", "id", "contentScore");
/**
* 构造函数
* @param $input_char 字符串的编码。默认 utf-8,可以省略
*/
function __construct($source, $input_char = "utf-8") {
$this->source = $source;
// DOM 解析类只能处理 UTF-8 格式的字符
$source = mb_convert_encoding($source, 'HTML-ENTITIES', $input_char);
// 预处理 HTML 标签,剔除冗余的标签等
$source = $this->preparSource($source);
// 生成 DOM 解析类
$this->DOM = new DOMDocument('1.0', $input_char);
try {
//libxml_use_internal_errors(true);
// 会有些错误信息,不过不要紧 :^)
if (!@$this->DOM->loadHTML('<?xml encoding="'.Readability::DOM_DEFAULT_CHARSET.'">'.$source)) {
throw new Exception("Parse HTML Error!");
}
foreach ($this->DOM->childNodes as $item) {
if ($item->nodeType == XML_PI_NODE) {
$this->DOM->removeChild($item); // remove hack
}
}
// insert proper
$this->DOM->encoding = Readability::DOM_DEFAULT_CHARSET;
} catch (Exception $e) {
// ...
}
}
/**
* 预处理 HTML 标签,使其能够准确被 DOM 解析类处理
*
* @return String
*/
private function preparSource($string) {
// 剔除多余的 HTML 编码标记,避免解析出错
preg_match("/charset=([\w|\-]+);?/", $string, $match);
if (isset($match[1])) {
$string = preg_replace("/charset=([\w|\-]+);?/", "", $string, 1);
}
// Replace all doubled-up <BR> tags with <P> tags, and remove fonts.
$string = preg_replace("/<br\/?>[ \r\n\s]*<br\/?>/i", "</p><p>", $string);
$string = preg_replace("/<\/?font[^>]*>/i", "", $string);
// @see https://github.com/feelinglucky/php-readability/issues/7
// - from http://stackoverflow.com/questions/7130867/remove-script-tag-from-html-content
$string = preg_replace("#<script(.*?)>(.*?)</script>#is", "", $string);
return trim($string);
}
/**
* 删除 DOM 元素中所有的 $TagName 标签
*
* @return DOMDocument
*/
private function removeJunkTag($RootNode, $TagName) {
$Tags = $RootNode->getElementsByTagName($TagName);
//Note: always index 0, because removing a tag removes it from the results as well.
while($Tag = $Tags->item(0)){
$parentNode = $Tag->parentNode;
$parentNode->removeChild($Tag);
}
return $RootNode;
}
/**
* 删除元素中所有不需要的属性
*/
private function removeJunkAttr($RootNode, $Attr) {
$Tags = $RootNode->getElementsByTagName("*");
$i = 0;
while($Tag = $Tags->item($i++)) {
$Tag->removeAttribute($Attr);
}
return $RootNode;
}
/**
* 根据评分获取页面主要内容的盒模型
* 判定算法来自:http://code.google.com/p/arc90labs-readability/
* 这里由郑晓博客转发
* @return DOMNode
*/
private function getTopBox() {
// 获得页面所有的章节
$allParagraphs = $this->DOM->getElementsByTagName("p");
// Study all the paragraphs and find the chunk that has the best score.
// A score is determined by things like: Number of <p>'s, commas, special classes, etc.
$i = 0;
while($paragraph = $allParagraphs->item($i++)) {
$parentNode = $paragraph->parentNode;
$contentScore = intval($parentNode->getAttribute(Readability::ATTR_CONTENT_SCORE));
$className = $parentNode->getAttribute("class");
$id = $parentNode->getAttribute("id");
// Look for a special classname
if (preg_match("/(comment|meta|footer|footnote)/i", $className)) {
$contentScore -= 50;
} else if(preg_match(
"/((^|\\s)(post|hentry|entry[-]?(content|text|body)?|article[-]?(content|text|body)?)(\\s|$))/i",
$className)) {
$contentScore += 25;
}
// Look for a special ID
if (preg_match("/(comment|meta|footer|footnote)/i", $id)) {
$contentScore -= 50;
} else if (preg_match(
"/^(post|hentry|entry[-]?(content|text|body)?|article[-]?(content|text|body)?)$/i",
$id)) {
$contentScore += 25;
}
// Add a point for the paragraph found
// Add points for any commas within this paragraph
if (strlen($paragraph->nodeValue) > 10) {
$contentScore += strlen($paragraph->nodeValue);
}
// 保存父元素的判定得分
$parentNode->setAttribute(Readability::ATTR_CONTENT_SCORE, $contentScore);
// 保存章节的父元素,以便下次快速获取
array_push($this->parentNodes, $parentNode);
}
$topBox = null;
// Assignment from index for performance.
// See http://www.peachpit.com/articles/article.aspx?p=31567&seqNum=5
for ($i = 0, $len = sizeof($this->parentNodes); $i < $len; $i++) {
$parentNode = $this->parentNodes[$i];
$contentScore = intval($parentNode->getAttribute(Readability::ATTR_CONTENT_SCORE));
$orgContentScore = intval($topBox ? $topBox->getAttribute(Readability::ATTR_CONTENT_SCORE) : 0);
if ($contentScore && $contentScore > $orgContentScore) {
$topBox = $parentNode;
}
}
// 此时,$topBox 应为已经判定后的页面内容主元素
return $topBox;
}
/**
* 获取 HTML 页面标题
*
* @return String
*/
public function getTitle() {
$split_point = ' - ';
$titleNodes = $this->DOM->getElementsByTagName("title");
if ($titleNodes->length
&& $titleNode = $titleNodes->item(0)) {
// @see http://stackoverflow.com/questions/717328/how-to-explode-string-right-to-left
$title = trim($titleNode->nodeValue);
$result = array_map('strrev', explode($split_point, strrev($title)));
return sizeof($result) > 1 ? array_pop($result) : $title;
}
return null;
}
/**
* Get Leading Image Url
*
* @return String
*/
public function getLeadImageUrl($node) {
$images = $node->getElementsByTagName("img");
if ($images->length && $leadImage = $images->item(0)) {
return $leadImage->getAttribute("src");
}
return null;
}
/**
* 获取页面的主要内容(Readability 以后的内容)
*
* @return Array
*/
public function getContent() {
if (!$this->DOM) return false;
// 获取页面标题
$ContentTitle = $this->getTitle();
// 获取页面主内容
$ContentBox = $this->getTopBox();
//Check if we found a suitable top-box.
if($ContentBox === null)
throw new RuntimeException(Readability::MESSAGE_CAN_NOT_GET);
// 复制内容到新的 DOMDocument
$Target = new DOMDocument;
$Target->appendChild($Target->importNode($ContentBox, true));
// 删除不需要的标签
foreach ($this->junkTags as $tag) {
$Target = $this->removeJunkTag($Target, $tag);
}
// 删除不需要的属性
foreach ($this->junkAttrs as $attr) {
$Target = $this->removeJunkAttr($Target, $attr);
}
$content = mb_convert_encoding($Target->saveHTML(), Readability::DOM_DEFAULT_CHARSET, "HTML-ENTITIES");
// 多个数据,以数组的形式返回
return Array(
'lead_image_url' => $this->getLeadImageUrl($Target),
'word_count' => mb_strlen(strip_tags($content), Readability::DOM_DEFAULT_CHARSET),
'title' => $ContentTitle ? $ContentTitle : null,
'content' => $content
);
}
function __destruct() { }
}在使用Typecho时,文章浏览次数统计算是最常用到的功能,把下面这段代码加到主题 functions.php 中,直接调用即可。代码加入了Cookie防刷新,这样文章浏览次数更真实。
function get_views($archive) {
$db = Typecho_Db::get();
$cid = $archive->cid;
//添加 table.contents.views 字段
if (!array_key_exists('views', $db->fetchRow($db->select()->from('table.contents')))) {
$db->query('ALTER TABLE `'.$db->getPrefix().'contents` ADD `views` INT(10) DEFAULT 0;');
}
$row = $db->fetchRow($db->select('views')->from('table.contents')->where('cid = ?', $cid));
$views = (int)$row['views'];
if ($archive->is('single')) {
$cookie = Typecho_Cookie::get('extend_views');
$cookie = $cookie ? explode(',', $cookie) : array();
if (!in_array($cid, $cookie)) {
$db->query($db->update('table.contents')->rows(array('views' => $views+1))->where('cid = ?', $cid));
$views = $views+1;
array_push($cookie, $cid);
$cookie = implode(',', $cookie);
Typecho_Cookie::set('extend_views', $cookie);
}
}
echo $views == 0 ? '暂无阅读' :'阅读量:' . $views;
}调用代码:
<?php get_views($this) ?>